10. Go语言编译器#TODO¶
10.1. 为什么要了解Go语言编译器¶
编译器是一个大型且复杂的系统,一个好的编译器会很好地结合形式语言理论、算法、人工智能、系统设计、计算机体系结构及编程语言理论。Go语言的编译器遵循了主流编译器采用的经典策略及相似的处理流程和优化规则(例如经典的递归下降的语法解析、抽象语法树的构建)。另外,Go语言编译器有一些特殊的设计,例如内存的逃逸等。在本章会介绍Go语言编译器的各个阶段。
注解
编译原理值得用一本书的笔墨去讲解,通过了解Go语言编辑器,不仅可以了解大部分高级语言编译器的一般性流程与规则,也能指导我们写出更加优秀的程序。很多Go语言的语法特性都离不开编译时与运行时的共同作用。
10.2. Go语言编译器的阶段¶
在经典的编译原理中,一般将编译器分为编译器前端、优化器和编译器后端。这种编译器被称为三阶段编译器(three-phase compiler)。其中
编译器前端主要专注于理解源程序、扫描解析源程序并进行精准的语义表达。
编译器的中间阶段(Intermediate Representation,IR)可能有多个,编译器会使用多个IR阶段、多种数据结构表示代码,并在中间阶段对代码进行多次优化。例如,识别冗余代码、识别内存逃逸等。编译器的中间阶段离不开编译器前端记录的细节。
编译器后端专注于生成特定目标机器上的程序,这种程序可能是可执行文件,也可能是需要进一步处理的中间形态obj文件、汇编语言等。

需要注意的是,编译器优化并不是一个非常明确的概念。优化的主要目的一般是降低程序资源的消耗,比较常见的是降低内存与CPU的使用率。但在很多时候,这些目标可能是相互冲突的,对一个目标的优化可能降低另一个目标的效率。同时,理论已经表明有一些代码优化存在着NP难题,这意味着随着代码的增加,优化的难度将越来越大,需要花费的时间呈指数增长。因为这些原因,编译器无法进行最佳的优化,所以通常采用一种折中的方案。
小技巧
通俗但不是很严谨的解释:
P类问题就是指那些计算机比较容易算出答案的问题。
NP类问题就是指那些已知答案以后计算机可以比较容易地验证答案的问题。
Go语言编译器一般缩写为小写的gc(go compiler),需要和大写的GC(垃圾回收)进行区分。Go语言编译器的执行流程可细化为多个阶段,包括词法解析、语法解析、抽象语法树构建、类型检查、变量捕获、函数内联、逃逸分析、闭包重写、遍历函数、SSA生成、机器码生成,如下图所示。后面将对这些阶段逐一进行分析。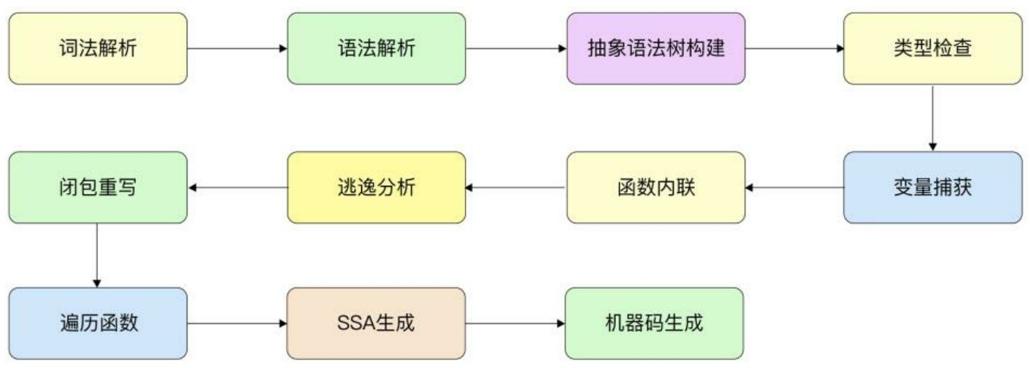
10.3. 词法解析¶
小技巧
和Go语言编译器有关的代码主要位于src/cmd/compile/internal目录下,在后面分析中给出的文件路径均默认位于该目录中。
在词法解析阶段,Go语言编译器会扫描输入的Go源文件,并将其符号(token)化。
例如
+和-操作符会被转换为_IncOp赋值符号
:=会被转换为_Define。
这些token实质上是用iota声明的整数,定义在syntax/tokens.go中。
1// Copyright 2016 The Go Authors. All rights reserved.
2// Use of this source code is governed by a BSD-style
3// license that can be found in the LICENSE file.
4
5package syntax
6
7type token uint
8
9//go:generate stringer -type token -linecomment tokens.go
10
11const (
12 _ token = iota
13 _EOF // EOF
14
15 // names and literals
16 _Name // name
17 _Literal // literal
18
19 // operators and operations
20 // _Operator is excluding '*' (_Star)
21 _Operator // op
22 _AssignOp // op=
23 _IncOp // opop
24 _Assign // =
25 _Define // :=
26 _Arrow // <-
27 _Star // *
28
29 // delimiters
30 _Lparen // (
31 _Lbrack // [
32 _Lbrace // {
33 _Rparen // )
34 _Rbrack // ]
35 _Rbrace // }
36 _Comma // ,
37 _Semi // ;
38 _Colon // :
39 _Dot // .
40 _DotDotDot // ...
41
42 // keywords
43 _Break // break
44 _Case // case
45 _Chan // chan
46 _Const // const
47 _Continue // continue
48 _Default // default
49 _Defer // defer
50 _Else // else
51 _Fallthrough // fallthrough
52 _For // for
53 _Func // func
54 _Go // go
55 _Goto // goto
56 _If // if
57 _Import // import
58 _Interface // interface
59 _Map // map
60 _Package // package
61 _Range // range
62 _Return // return
63 _Select // select
64 _Struct // struct
65 _Switch // switch
66 _Type // type
67 _Var // var
68
69 // empty line comment to exclude it from .String
70 tokenCount //
71)
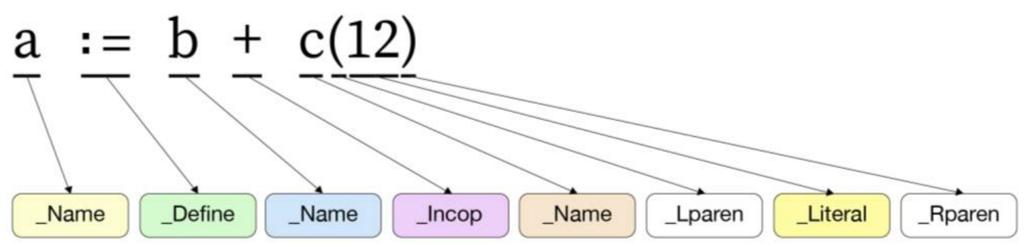
符号化保留了Go语言中定义的符号,可以识别出错误的拼写。同时,字符串被转换为整数后,在后续的阶段中能够被更加高效地处理。下图为一个示例,展现了将表达式a:=b+c(12)符号化之后的情形。代码中声明的标识符、关键字、运算符和分隔符等字符串都可以转化为对应的符号。
Go语言标准库go/scanner、go/token也提供了许多接口用于扫描源代码。在下例中,我们将使用这些接口模拟对Go文本文件的扫描。
package main
import (
"fmt"
"go/scanner"
"go/token"
)
func main() {
src := []byte("cos(x) + 2i*sin(x) // Euler")
//初始化scanner
var s scanner.Scanner
fset := token.NewFileSet()
file := fset.AddFile("", fset.Base(), len(src))
s.Init(file, src, nil, scanner.ScanComments)
//扫描
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n",fset.Position(pos), tok, lit)
}
}
在这个例子中,src为进行词法扫描的表达式,可以将其模拟为一个文件并调用scanner.Scanner词法,扫描后分别打印出token的位置、符号及其字符串字面量。每个标识符与运算符都被特定的token代替,例如2i被识别为复数IMAG,注释被识别为COMMENT。
1:1 IDENT "cos"
1:4 ( ""
1:5 IDENT "x"
1:6 ) ""
1:8 + ""
1:10 IMAG "2i"
1:12 * ""
1:13 IDENT "sin"
1:16 ( ""
1:17 IDENT "x"
1:18 ) ""
1:21 ; "\n"
1:21 COMMENT "// Euler"
10.4. 语法解析¶
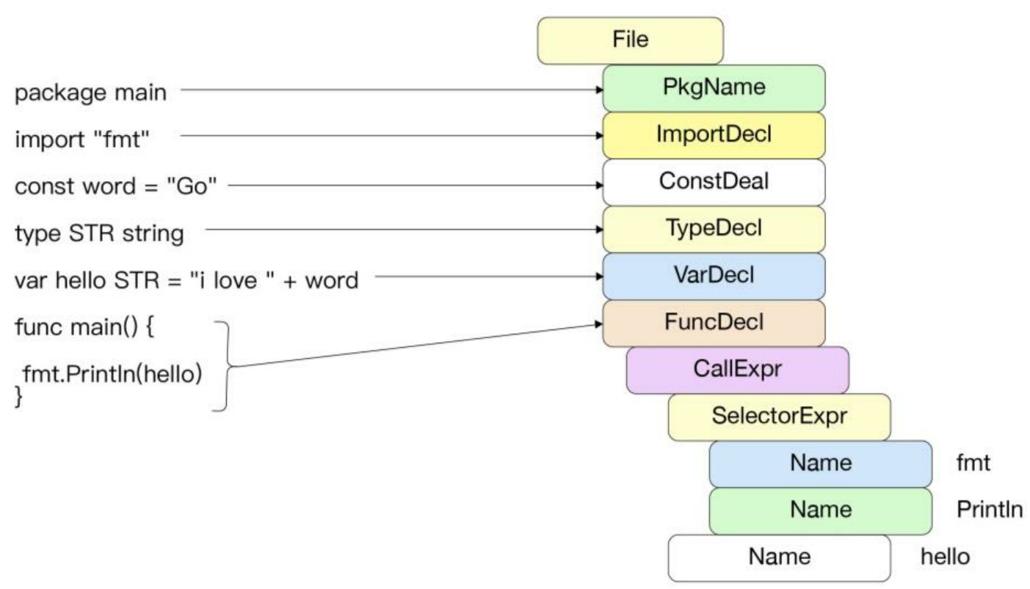
词法解析阶段结束后,需要根据Go语言中指定的语法对符号化后的Go文件进行解析。Go语言采用了标准的自上而下的递归下降(Top-Down Recursive-Descent)算法,以简单高效的方式完成无须回溯的语法扫描,核心算法位于syntax/nodes.go及syntax/parser.go中。下图为Go语言编译器对文件进行语法解析的示意图。在一个Go源文件中主要有包导入声明(import)、静态常量(const)、类型声明(type)、变量声明(var)及函数声明(func)。
注解
源文件中的每一种声明都有对应的语法,递归下降通过识别初始的标识符,例如_const,采用对应的语法进行解析。这种方式能够较快地解析并识别可能出现的语法错误。每一种声明语法在Go语言规范中都有定义。
// 包导入声明
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
// 静态常量
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
// 类型声明
TypeSpec = identifier [ TypeParams ] [ "=" ] Type .
// 变量声明
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .
函数声明是文件中最复杂的一类语法,因为在函数体的内部可能有多种声明、赋值(例如:=)、表达式及函数调用等。例如defer语法为defer Expression,其后必须跟一个函数或方法。
每一种声明语法或者表达式都有对应的结构体,例如a := b+f(89)对应的结构体为赋值声明AssignStmt。Op代表当前的操作符,即:=,Lhs与Rhs分别代表左右两个表达式。
AssignStmt struct {
Op Operator // 0 means no operation
Lhs, Rhs Expr // Rhs == nil means Lhs++ (Op == Add) or Lhs-- (Op == Sub)
simpleStmt
}
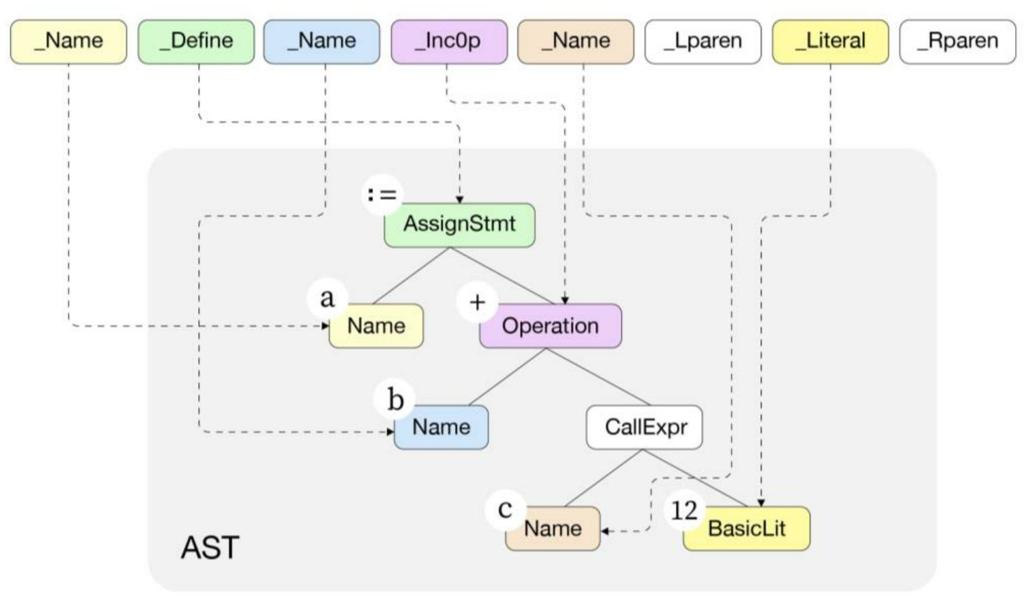
语法解析丢弃了一些不重要的标识符,例如括号(,并将语义存储到了对应的结构体中。语法声明的结构体拥有对应的层次结构,这是构建抽象语法树的基础。下图为a := b+c(12)语句被语法解析后转换为对应的syntax.AssignStmt结构体之后的情形。
最顶层的
Op操作符为token.Def(:=)Lhs表达式类型为标识符syntax.Name,值为标识符a。Rhs表达式为syntax.Operator加法运算。加法运算左边为标识符b,右边为函数调用表达式,类型为CallExpr。其中,函数名c的类型为
syntax.Name,参数为常量类型syntax.BasicLit,代表数字12。
10.5. 抽象语法树构建¶
编译器前端必须构建程序的中间表示形式,以便在编译器中间阶段及后端使用。抽象语法树(Abstract Syntax Tree,AST)是一种常见的树状结构的中间态。
在Go语言源文件中的任何一种import、type、const、func声明都是一个根节点,在根节点下包含当前声明的子节点。如下decls函数将源文件中的所有声明语句转换为节点(Node)数组。核心逻辑位于noder/noder.go中。
func (p *noder) decls(decls []syntax.Decl) (l []ir.Node) {
var cs constState
for _, decl := range decls {
p.setlineno(decl)
switch decl := decl.(type) {
case *syntax.ImportDecl:
p.importDecl(decl)
case *syntax.VarDecl:
l = append(l, p.varDecl(decl)...)
case *syntax.ConstDecl:
l = append(l, p.constDecl(decl, &cs)...)
case *syntax.TypeDecl:
l = append(l, p.typeDecl(decl))
case *syntax.FuncDecl:
l = append(l, p.funcDecl(decl))
default:
panic("unhandled Decl")
}
}
return
}
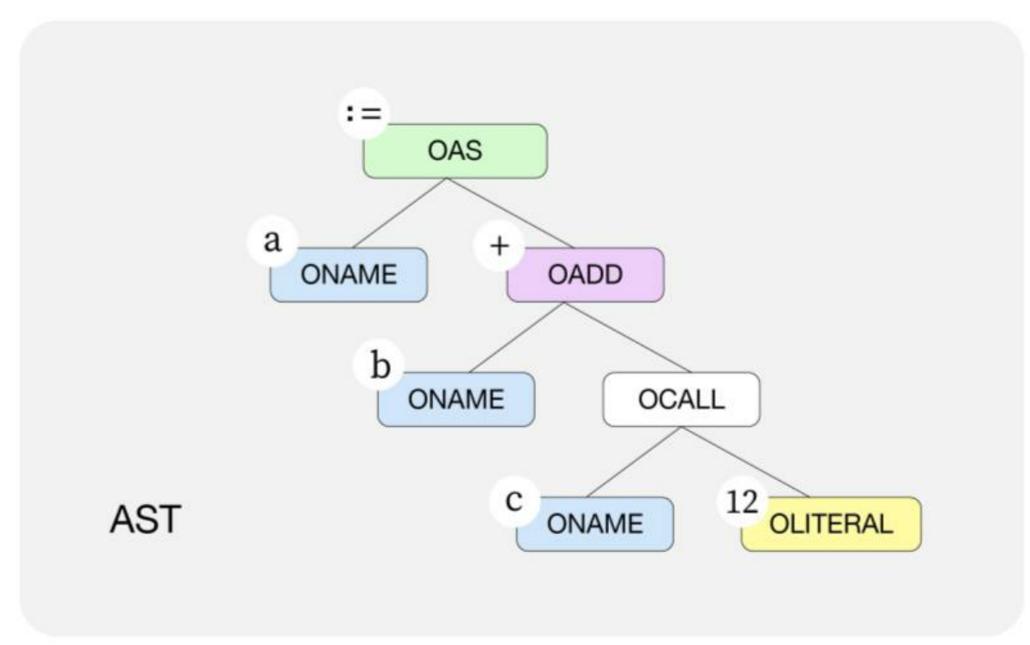
每个节点都包含了当前节点属性的Op字段,定义在ir/node.go中,以O开头。与词法解析阶段中的token相同的是,Op字段也是一个整数。不同的是,每个Op字段都包含了语义信息。例如,当一个节点的Op操作为OAS时,该节点代表的语义为Left:=Right,而当节点的操作为OAS2时,代表的语义为x,y,z=a,b,c。
const (
OXXX Op = iota
// names
ONAME // var or func name
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name
OPACK // import
OLITERAL // literal
ONIL // nil
// expressions
OADD // X + Y
OSUB // X - Y
OOR // X | Y
OXOR // X ^ Y
OADDSTR // +{List} (string addition, list elements are strings)
OADDR // &X
OANDAND // X && Y
......
以a := b+c(12)为例,该赋值语句最终会变为如下图所示的抽象语法树。节点之间具有从上到下的层次结构和依赖关系。
10.6. 类型检查¶
完成抽象语法树的初步构建后,就进入类型检查阶段遍历节点树并决定节点的类型。
这其中包括了语法中明确指定的类型,例如var a int,也包括了需要通过编译器类型推断得到的类型。例如,a := 1中的变量a与常量1都未直接声明类型,编译器会自动推断出节点常量1的类型为TINT(),并自动推断出a的类型为TINT()。相关内容在后面有更深入的分析。
在类型检查阶段,会对一些类型做特别的语法或语义检查。例如:
引用的结构体字段是否是大写可导出的?
数组字面量的访问是否超过了其长度?
数组的索引是不是正整数?
除此之外,在类型检查阶段还会进行其他工作。例如:计算编译时常量、将标识符与声明绑定等。类型检查的核心逻辑位于typecheck/typecheck.go中。
10.7. 变量捕获类型检查阶段完成后,Go语言编译器将对抽象语法树进行分析及重构,从而完成一系列优化。¶
变量捕获主要是针对闭包场景而言的,由于闭包函数中可能引用闭包外的变量,因此变量捕获需要明确在闭包中通过值引用或地址引用的方式来捕获变量。下面的例子中有一个闭包函数,在闭包内引入了闭包外的a、b变量,由于变量a在闭包之后进行了其他赋值操作,因此在闭包中,a、b变量的引用方式会有所不同。在闭包中,必须采取地址引用的方式对变量a进行操作,而对变量b的引用将通过直接值传递的方式进行。
func main() {
a := 1
b := 2
go func() {
fmt.Println(a, b)
}()
a = 99
}
在Go语言编译的过程中,可以通过如下方式查看当前程序闭包变量捕获的情况。从输出中可以看出,a采取ref引用传递的方式,而b采取了值传递的方式。assign=true代 表变量a在闭包完成后又进行了赋值操作。
go tool compile -m=2 main.go|grep capturing
main.go:6:2: main capturing by ref: a (addr=false assign=true width=8)
main.go:7:2: main capturing by value: b (addr=false assign=false width=8)
闭包变量捕获的核心逻辑位于walk/closure.go的capturevars函数中。
10.8. 函数内联¶
函数内联指将较小的函数直接组合进调用者的函数。
这是现代编译器优化的一种核心技术。函数内联的优势在于,可以减少函数调用带来的开销。
对于Go语言来说,函数调用的成本在于参数与返回值栈复制、较小的栈寄存器开销以及函数序言部分的检查栈扩容(Go语言中的栈是可以动态扩容的)。同时,函数内联是其他编译器优化(例如无效代码消除)的基础。我们可以通过一段简单的程序衡量函数内联带来的效率提升
如下所示,使用bench对max函数调用进行测试。当我们在函数的注释前方加上//go:noinline时,代表当前函数是禁止进行函数内联优化的。取消该注释后,max函数将会对其进行内联优化。
package main
import "testing"
//go:noinline
func max(a, b int) int {
if a > b {
return a
}
return b
}
var Result int
func BenchmarkMax(b *testing.B) {
var r int 0
for i := 0; i < b.N; i++ {
r = max(-1, i)
}
Result = r
}