1. Docker 入门概述¶
1.1. 什么是Docker¶
Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。它基于 Google 公司推出的 Go 语言实现。 项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,项目代码在 GitHub 上进行维护。
Docker 自开源后受到广泛的关注和讨论,以至于 dotCloud 公司后来都改名为 Docker Inc。Redhat 已经在其 RHEL6.5 中集中支持 Docker;Google 也在其 PaaS 产品中广泛应用。
Docker 项目的目标是实现轻量级的操作系统虚拟化解决方案。 Docker 的基础是 Linux 容器(LXC)等技术。
在 LXC 的基础上 Docker 进行了进一步的封装,让用户不需要去关心容器的管理,使得操作更为简便。用户操作 Docker 的容器就像操作一个快速轻量级的虚拟机一样简单。
下面的图片比较了 Docker 和传统虚拟化方式的不同之处,可见容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统方式则是在硬件层面实现。
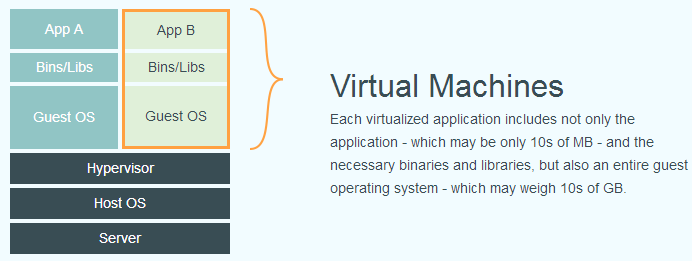

小技巧
可以看到,一个宿主机上的所有Docker容器都是共享一个宿主机内核的,这其实是操作系统级别的隔离,其他的开源容器产品如Kata Container则实现了内核级别的隔离
1.2. 为什么选择Docker¶
为什么要使用Docker?Docker用在什么地方?针对“为什么”的简要答案如下:
更高效的利用系统资源
由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,
Docker对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟,而
Docker容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。一致的运行环境
开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而
Docker的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。持续交付和部署
对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
使用
Docker可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成(Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。而且使用
Dockerfile使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。更轻松的迁移
由于
Docker确保了执行环境的一致性,使得应用的迁移更加容易。Docker可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
1.3. 容器对比传统虚拟机总结¶
特性 |
容器 |
虚拟机 |
|---|---|---|
启动 |
秒级 |
分钟级 |
硬盘使用 |
一般为 |
一般为 |
性能 |
接近原生 |
原生 |
系统支持量 |
单机支持上千个容器 |
一般几十个 |
1.4. Docker的底层技术¶
Docker 本质就是宿主机的一个特殊进程,Docker 是通过 namespace 实现资源隔离,通过cgroup 实现资源限制,通过写时复制技术(copy-on-write)实现了高效的文件操作(类似虚拟机的磁盘比如分配 500g 并不是实际占用物理磁盘 500g)
1.4.1. Namespaces¶
命名空间 (namespaces) 是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用个人 PC 时,我们并没有运行多个完全分离的服务器的需求,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这是我们不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。而 Docker 其实就通过 Linux 的 Namespaces 技术来实现的对不同的容器进行隔离。
当我们运行(docker run 或者 docker start)一个 Docker 容器时,Docker 会为该容器设置一系列的 namespaces,这些 namespaces 提供了一层隔离,容器的各个方面都在单独的 namespace 中运行,并且对其的访问仅限于该 namespace。
Docker 在 Linux 上使用以下几个命名空间(上面说的各个方面):
pid namespace:用于进程隔离(PID:进程ID)
net namespace:管理网络接口(NET:网络)
ipc namespace:管理对 IPC 资源的访问(IPC:进程间通信(信号量、消息队列和共享内存))
mnt namespace:管理文件系统挂载点(MNT:挂载)
uts namespace:隔离主机名和域名
user namespace:隔离用户和用户组(3.8以后的内核才支持)
1.4.2. CGroups¶
我们通过 Linux 的 namespaces 技术为新创建的进程隔离了文件系统、网络、进程等资源,但是 namespaces 并不能够为我们提供物理资源上的隔离,比如 CPU、内存、IO 或者网络带宽等,所以如果我们运行多个容器的话,则容器之间就会抢占资源互相影响了,所以对容器资源的使用进行限制就非常重要了,而 Control Groups(CGroups)技术就能够隔离宿主机上的物理资源。CGroups 由 7 个主要的子系统组成:分别是 cpuset、cpu、cpuacct、blkio、devices、freezer、memory,不同类型资源的分配和管理是由各个 CGroup 子系统负责完成的。
1.4.2.1. CGroup 简介¶
在 CGroup 中,所有的任务就是一个系统的一个进程,而 CGroup 就是一组按照某种标准划分的进程,在 CGroup 这种机制中,所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。
CGroup 具有以下几个特点:
CGroup 的 API 以一个伪文件系统(/sys/fs/cgroup/)的实现方式,用户的程序可以通过文件系统实现 CGroup 的组件管理
CGroup 的组件管理操作单元可以细粒度到线程级别,用户可以创建和销毁 CGroup,从而实现资源载分配和再利用
所有资源管理的功能都以子系统(cpu、cpuset 这些)的方式实现,接口统一子任务创建之初与其父任务处于同一个 CGroup 的控制组
另外 CGroup 具有四大功能:
资源限制:可以对任务使用的资源总额进行限制
优先级分配:通过分配的 cpu 时间片数量以及磁盘 IO 带宽大小等,实际上相当于控制了任务运行优先级
资源统计:可以统计系统的资源使用量,如 cpu 时长,内存用量等
任务控制:cgroup 可以对任务执行挂起、恢复等操作
1.4.3. UnionFS¶
Linux 的命名空间和控制组分别解决了不同资源隔离的问题,前者解决了进程、网络以及文件系统的隔离,后者实现了 CPU、内存等资源的隔离,但是在 Docker 中还有另一个非常重要的问题需要解决 - 也就是镜像。
镜像到底是什么,它又是如何组成和组织的呢?而这其中最重要的概念就是镜像层(Layers)(如下图)的概念,而镜像层依赖于一系列的底层技术,比如文件系统(filesystems)、写时复制(copy-on-write)、联合挂载(union mounts)等。
